Moonpool and OCaml5 in Imandrax
by Simon Cruanes (@c-cube) on nov 12, 2025.
- Introduction
- Brief overview of concurrency in OCaml 4.xx
- Direct-style concurrency on OCaml5
- Moonpool in imandrax
- Case study:
Parse_import_graph - What about async IOs?
- Conclusion
Introduction
OCaml 5.0 was released on December 2022, with exciting new features for concurrency in OCaml.1 The community reacted, as befits OCaml, by starting multiple new concurrency libraries such as Eio, Miou, picos, Domainslib, Abb (announce), and my (@c-cube) own library, Moonpool.
In this essay blog post I will explain how we use Moonpool at Imandra
in our next-generation proof assistant, imandrax.
Imandrax is a proprietary proof assistant and automated prover that underpins much of our internal operations. It is based on a pure subset of OCaml and combines techniques from the Boyer-Moore world (as seen in ACL2) and SMT solvers, in our case using Z3 via its OCaml bindings. Imandrax can be used either from the command line; from an editor using its integrated Language Server (LSP); or via a HTTP API for programmatic use. For context, the project clocks at around 108 kloc of OCaml even before considering dependencies. Below is a screenshot of our VSCode plugin, showing a simple proof in imandrax.
With that out of the way,2 let’s talk about concurrency and parallelism in OCaml and then in imandrax!
Brief overview of concurrency in OCaml 4.xx
Historically, concurrency in OCaml 4.xx and earlier was done in one of the following ways:
-
System threads, but with a GIL-like runtime lock which prevents two threads from running in parallel (unless one of them is inside a lock-releasing C call). This means only one core can be used by a given process, and it also often means using blocking IO primitives. In OCaml it could look like this:
let handle_client (input:in_channel) (output:out_channel) : unit = try while true do let line = input_line input in Printf.printf "read %S from client.\n" line; output_line output (String.uppercase_ascii line) done with End_of_file -> () (* in the server accept loop *) let th: Thread.t = Thread.create (fun () -> handle_client input output) () -
Cooperative concurrency via Lwt or Janestreet’s Async. This style builds on some system event loop (
epoll,kqueue, etc) to schedule promises, and provides a concurrency monad to chain the promises together. It unlocks asynchronous IOs and can potentially enable higher levels of concurrency than plain threads, but it’s still limited to a single core and can lead to some interesting bugs if an expensive CPU-bound task runs in the event loop.The monadic style would look like this (some error handling omitted):
let rec handle_client input output : unit Lwt.t = Lwt_io.read_line_opt input >>= fun line_opt -> match line_opt with | None -> Lwt.return () (* done *) | Some line -> Lwt_io.write_line output (String.uppercase_ascii line) >>= fun () -> handle_client input outputThere are preprocessors and other ways to prettify the code, but ultimately this is what the code is like. Among other downsides, stack traces are completely useless for exceptions raised from Lwt programs.
The most active web framework for OCaml, Dream,
is based on Lwt3 and thus, on Linux, on epoll.
Direct-style concurrency on OCaml5
With OCaml5 and effects we’re seeing direct style concurrency rise through the
use of algebraic effects.
This means, in effect, no more concurrency monad: instead of stitching together a sequence of promises using >>=, we can write direct code and suspend the current fiber/task until a promise is resolved using some form of await effect.
Eio: Lwt’s replacement?
The most popular OCaml5 concurrency library
is probably Eio which provides lightweight fibers
on top of an event loop (epoll, io_uring, kqueue, etc).
An example taken directly from the README:
# let main _env =
Fiber.both
(fun () -> for x = 1 to 3 do traceln "x = %d" x; Fiber.yield () done)
(fun () -> for y = 1 to 3 do traceln "y = %d" y; Fiber.yield () done) ;;
# Eio_main.run main
+x = 1
+y = 1
+x = 2
+y = 2
+x = 3
+y = 3
- : unit = ()
Here we see that two distinct fibers (lightweight cooperative tasks) are started concurrently. Each of them, in a loop, prints a message, and yields to the scheduler, thus allowing the other fiber to have a turn.
Further down in the README we see:
let cli ~stdin ~stdout =
let buf = Eio.Buf_read.of_flow stdin ~initial_size:100 ~max_size:1_000_000 in
while true do
let line = Eio.Buf_read.line buf in
traceln "> %s" line;
match line with
| "h" | "help" -> Eio.Flow.copy_string "It's just an example\n" stdout
| x -> Eio.Flow.copy_string (Fmt.str "Unknown command %S\n" x) stdout
done
It’s clearly direct style: a while loop, IO operations resemble normal
function calls, no monad in sight, stack traces are nice and pretty.
Eio normally still runs on a single thread, even though it has some facilities
to manage a domain pool
for background tasks.
This is not intended as a full introduction to Eio, but we can mention a few more things before moving on:
- it is very opinionated and forces users to thread a set of capabilities around IO operations. The 0.1 announce spilled a lot of ink on that topic.
- it implements structured concurrency. See Trio for a very readable overview of this neat topic.
- it defaults to
io_uringon Linux. - it has a neat tracing system based on OCaml’s new Runtime_events system.
Domains
A subtle aspect of OCaml5’s new support for multicore programming is that there’s both the pre-existing threads and the new concept of domains. The go-to library for domain-based parallelism is domainslib.
Domains are heavier threads that have their own slice of runtime and can actually run in parallel. Each domain might have multiple threads that share its runtime slice and cannot run in parallel of one another.
It is recommended to not have more domains than CPU cores. This makes domains a very scarce resource, unlike threads, and it means it can be bad practice for a library to start domains unilaterally.
Moonpool
So where does Moonpool fit in this landscape? Moonpool was designed to bypass the lack of compositionality of domains, by allowing multiple thread pools to co-exist while spreading their threads over multiple domains. Moonpool was first released in june 2023 (initial announce for its 0.1) under the MIT license, and has been continuously developed since. The development was driven in no small part by our use of it in imandrax.
The core concept of Moonpool is Moonpool.Runner.t, alongside a promise
type 'a Moonpool.Fut.t.
Here is a very simplified view of Moonpool’s main interface:
(read docs here)
(** thread-safe promises *)
module Fut : sig
type 'a t
(** a promise returning a ['a] *)
val await : 'a t -> 'a
(** suspend the caller task until promise is resolved,
then get the promise's result. *)
val make : unit -> 'a t
val fulfill : 'a t -> 'a -> unit
end
(** A task to run on a thread pool *)
type task = unit -> unit
(** The interface for runners *)
module Runner : sig
type t = {
run_async: task -> unit;
shutdown: unit -> unit;
size: unit -> int;
num_tasks: unit -> int;
}
end
(** runs a task on the given pool *)
val run_async : Runner.t -> task -> unit
(** spawn a task on the given pool, returning a promise *)
val spawn : Runner.t -> (unit -> 'a) -> 'a Fut.t
(** create a new work stealing pool *)
val ws_pool : ?num_threads:int -> unit -> Runner.t
So the user can create one or more pools (the type Runner.t) of worker threads,
and then run tasks on them, either with run_async or spawn.
These workers are preemptive, not cooperative, based on Thread.t. It’s fine to have hundreds of workers
spread among multiple pools even on a 16 core machine, which means you can have
multiple pools without having to worry about exceeding 16 workers like you’d do
if they used a full domain.
There is currently no dedicated IO facility, the focus is on CPU heavy tasks.
To summarize some of the design points:
- explicit
Runner.tinterface, so it’s possible to choose on which pool a particular task runs, and have multiple possible implementations of such runners; - use OCaml5’s effects to be able to
awaita promise, provide parallel primitives, etc. without monadic contamination and while preserving stack traces; - the promises are thread safe and can be
awaited from other runners safely. Promises come from picos, an attempt at defining common foundations for the various multicore libraries in the interest of cross-compatibility.
More on the design and goals of Moonpool can be found on the initial release announce over discuss.
An example with Moonpool: basic approximation of π
One of the basic benchmarks
in Moonpool computes a (simple) approximation
of pi using floats.
The parallel approach leads to a 11x speedup on
my Intel i7-12700, with a variant of the code below.
(* sequential version: *)
let run_sequential (num_steps : int) : float =
let@ _trace_span = Trace.with_span ~__FILE__ ~__LINE__ "pi.seq" in
let step = 1. /. float num_steps in
let sum = ref 0. in
for i = 0 to num_steps - 1 do
let x = (float i +. 0.5) *. step in
sum := !sum +. (4. /. (1. +. (x *. x)))
done;
let pi = step *. !sum in
pi
(* parallel version using fork-join over some Moonpool runner,
via a "parallel for" primitive *)
let run_fork_join num_steps : float =
let@ pool = Moonpool.Ws_pool.with_ () in
let num_tasks = Ws_pool.size pool in
let step = 1. /. float num_steps in
let global_sum = Lock.create 0. in
(* start a task on the pool and block until it's done *)
Ws_pool.run_wait_block pool (fun () ->
(* parallel for, running on the pool and await-ing the subtasks *)
Moonpool_forkjoin.for_
~chunk_size:(3 + (num_steps / num_tasks))
num_steps
(fun low high ->
let sum = ref 0. in
for i = low to high do
let x = (float i +. 0.5) *. step in
sum := !sum +. (4. /. (1. +. (x *. x)))
done;
let sum = !sum in
Lock.update global_sum (fun n -> n +. sum)));
let pi = step *. Lock.get global_sum in
pi
And hyperfine tells us:
./_build/default/benchs/pi.exe -n 100_000_000 -mode forkjoin -kind=pool ran
11.07 ± 1.36 times faster than ./_build/default/benchs/pi.exe -n 100_000_000 -mode=seq
Moonpool in imandrax
Right, so, where were we? We were talking about imandrax, a proof assistant with a heavy focus on proof automation.
The motivation for all this elaborate thread pool dance is simple: proof automation is really CPU heavy, and we wanted to run it in background tasks. In 2025, blocking the whole REPL because we’re asking Z3 to find a counter-model feels suboptimal. Even worse would be to block the LSP server and render it unresponsive while we check theorems in the current editor buffer, or to block the whole HTTP server while processing an API call!
So, we use Moonpool to run most of the non-trivial computations in thread pools.
- In a large portion of the codebase, a
Moonpool.Runner.tis in scope so it can be used to accelerate basic computations. Such tasks include, among others:- (de)compressing a list of blobs using
zlib, using fork-join to parallelize the work - traversing the user’s project tree to find
dunefiles (we walk the directory tree in parallel, one task per sub-directory) - various other parallel graph traversals (e.g. computing dependencies between content-addressed serialized values)
- (de)compressing a list of blobs using
- Parsing, typechecking, and the initial computation of proof obligations (“POs”)
is done with file-level parallelism. If we check file
d.imland it imports filesa.iml,b.iml, andc.iml, we will parse and typecheck these in parallel background tasks. This becomes more impactful for larger developments with many files. - LSP queries are processed in their individual tasks in a dedicated thread pool, which is kept separate from the normal background-task pool.
- for the HTTP server, we currently spawn a thread per connection because some of them might be long lived. HTTP isn’t currently a bottleneck for us.
- The main function still runs in a (trivial) Moonpool runner: we call
Moonpool_fib.main the_real_main4 and it callsthe_real_mainimmediately. The point of this is that it installs effect handlers so that we can callMoonpool.Fut.awaitfrom within the main function, too.
Here’s a trace of an execution of imandrax-cli (visualized with perfetto,
produced using heavy ocaml-trace instrumentation)
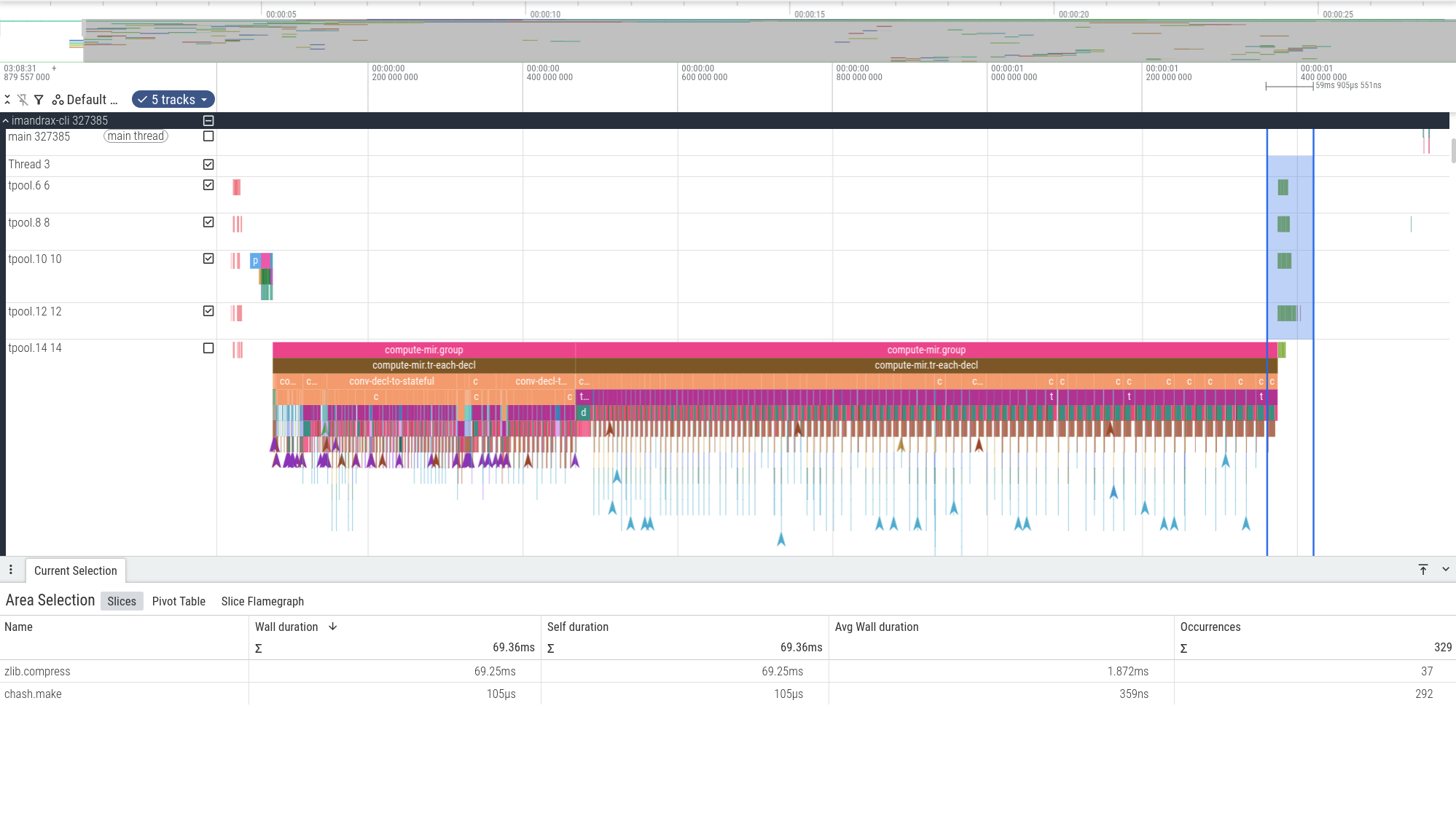
- on the left, the thin pink bands are the initial traversal of the source directory
to look for
dunefiles. - on the right, the selected blue area contains a bunch of tasks that decompress
zlibblobs and perform some Blake3 hashing for content-addressing purposes.5 - in the center, the parsing, typechecking and subsequent computation of POs for two modules. It’s sequential because each PO depends on the previous one.
Here’s a trace of parallel typechecking and PO computation in the LSP server, after opening a large development in VSCode:
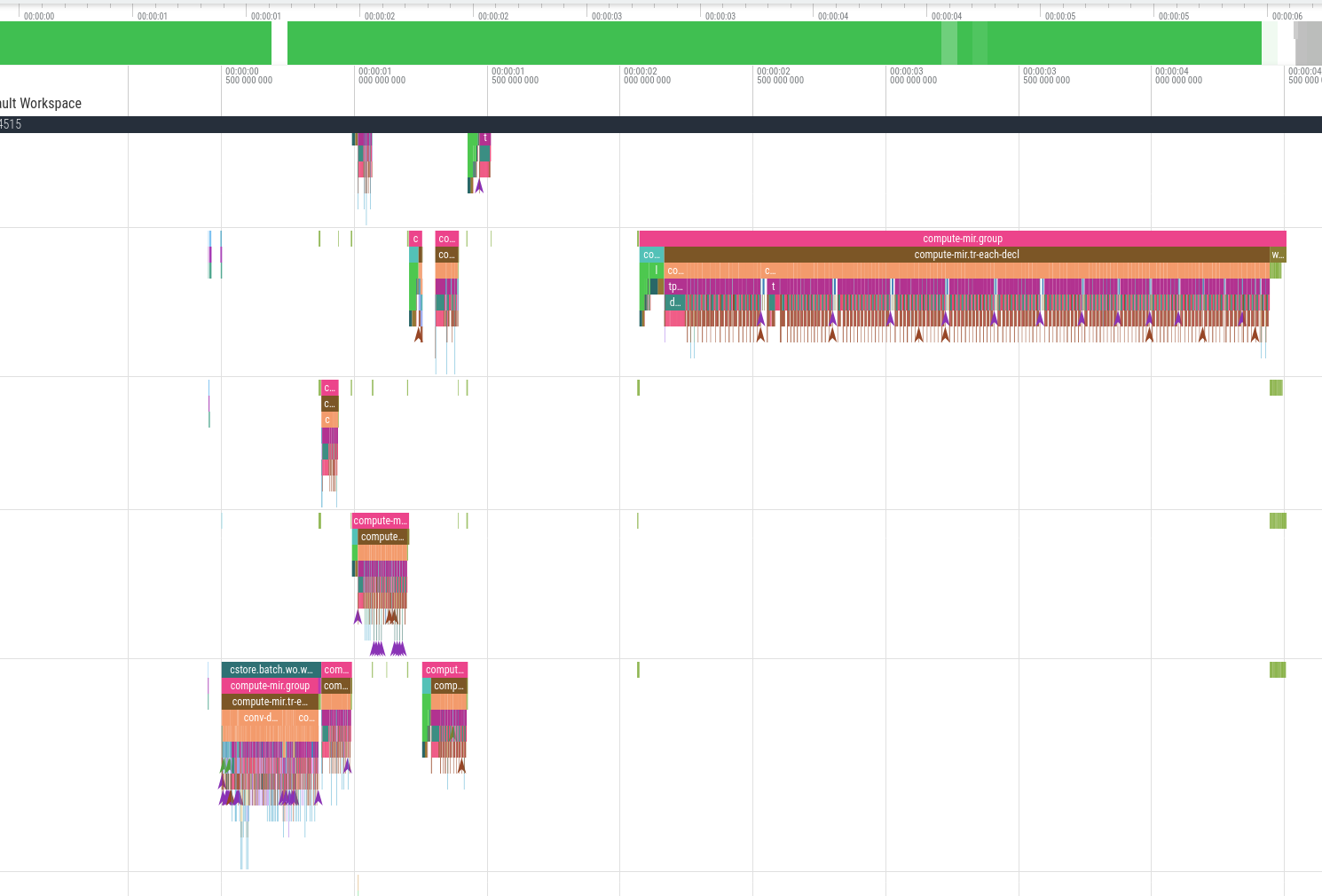
Some tasks are still very sequential! But do note that tasks on the left being spread between multiple worker threads. We also have parallel compression on the right (the green bands). The LSP server also uses background tasks for parallel parsing, LSP query handling, etc.
Running the proof obligations
Funnily enough, we started using Moonpool for a use case that’s not served by it anymore: actual theorem proving.
The heavy computations associated with theorem proving (Boyer-Moore style waterfall, SMT solving, simplifications, rewriting, etc.) used to run directly on a thread pool, but now run in worker sub-processes.
There’s multiple reasons for that. Z3 OCaml bindings are fiddly and might leak memory, or, even worse, segfault. Enforcing timeouts can be tricky. It makes sense to isolate the heavy lifting in a disposable sub-process so that crashes or leaks don’t affect the main imandrax process. Once the sub-process dies, the OS cleans up.
Here is a trace obtained by running the imandrax cli on a problem:

We can see the thin long blue line, that’s the main process. The other lines are individual worker processes that it spawned. Each worker has its own small thread pool for basic concurrency needs. Some workers can live for a while.
Parallelization levels
Running tasks in parallel doesn’t simply measure Moonpool’s performance, because we do solve proof obligations in worker subprocesses. Here we see that with at most 8 worker processes at a time, imandrax manages to use 8.2 CPU cores on a decomposition task.
$ perf stat ./_build/default/src/cli/imandrax_cli.exe check test/iml/decomp.iml -j 8
Success: 59/59 POs succeeded.
Performance counter stats for './_build/default/src/cli/imandrax_cli.exe check test/iml/decomp.iml -j 8':
31,831,740,539 task-clock:u # 8.248 CPUs utilized
[…]
3.859512934 seconds time elapsed
Moonpool’s influence on the codebase
So, that’s how we use Moonpool as the foundation for concurrency in imandrax. Since the previous system was REPL-based and sequential, we had opportunity to learn a lot by experimenting with this new world of direct-style concurrency. (…new in OCaml, anyway)
Over time, we’ve converged on some useful patterns. They might not be universally applicable but they do work for us. Some of them are well known! Here’s a few:
Local mutation, immutable long-lived data.
Data that is serialized, passed to other tasks, kept for a long time, etc. is immutable in most cases. We don’t want to needlessly worry about race conditions.
On the other hand, when processing a single task, we use a lot of mutations, probably more than the average OCaml program. We just make sure they don’t escape 😁.
Runners are passed explicitly
A lot of the code is passed some sort of context or state (a record with… stuff).
It often includes a Moonpool.Runner.t for concurrency needs. There is not much
global state, and no global runner.
Switches
We have a Switch.t type that’s loosely inspired by Lwt_switch.t.:
type t [@@deriving show]
(** A thread-safe switch for cancellation *)
val create : ?parent:t -> unit -> t
(** New switch.
@param parent
inherit from this switch. It means that the result switches off if the
parent does, but conversely we can turn the result off without affecting
the parent. In other words, this switch's lifetime is a subset of the
parent's lifetime *)
val on_turn_off : t -> (unit -> unit) -> unit
(** [on_turn_off sw f] will call [f()] when [sw] is turned off. If [sw] is
already off then [f()] is called immediately. {b NOTE} [f] really should not
fail. *)
val is_on : t -> bool
val is_off : t -> bool
val turn_off : t -> unit
(** If it was on, turn the switch off and call all the callbacks. *)
We pass this around in much of the code base as an ~(active:Switch.t)
parameter, or as part of a larger context record.
Resources can be registered for cleanup on the current switch (useful in a concurrent context
where RAII-ish isn’t always suitable).
In CPU-bound tasks, it is on us to regularly check that the switch is on, and exit early if it’s off. Cancellation is a hard problem!
Compute/IO segregation
We try to reduce the amount of “shotgun IOs” we do. A worker subprocess, responsible for processing one (1) task, will thus:
- read the entirety of the serialized task and its (bundled) dependencies,
from the parent process, on
stdin. The parent process already took care of the bundling so we don’t have to do a back and forth. - deserialize the task description into usable logic structures.
- actually process the task, calling Z3, running a refinement loop, inductive waterfall, etc. where all the magic happens. The only IO we do here is sending progress updates to the parent, logging, and tracing.
- serialize results.
- write serialized results on
stdoutfor the parent to read.
RAII-ish
This is a bit of OCaml inside-baseball. For safe resource handling, we often adopt this pattern:
(* [let@ x = e1 in e2] is the same as [e1 (fun x -> e2)] *)
let (let@) = (@@)
(* look at this cleanup! *)
let example1 =
let@ input = CCIO.with_file_in "foo.txt" in
process input
(* file handle closed here *)
let example2 =
(* acquire a DB connection from a pool *)
let@ db_conn = Db_pool.with_connection db_pool in
(* run a query using the connection *)
run_sql db_conn "select a, b from whatever;"
(* DB connection returned to pool here, at scope exit *)
It works surprisingly well to make sure we don’t leak resources, as long as the resources’ lifetimes are purely lexical in scope. We use this for locks, tracing spans, error handlers, database connections, client sockets, etc.
RAII-ish Lock
Whenever we have actual shared data (some tables in parallel graph traversals, etc.) we use this small mutex wrapper:
module Lock = struct
type 'a t = {
mutex: Mutex.t;
mutable content: 'a;
}
let create content : _ t = { mutex = Mutex.create (); content }
let with_lock (self:_ t) f =
Mutex.protect self.mutex (fun () -> f self.content)
end
let my_tbl: (int,bool) Hashtbl.t Lock.t =
Lock.create @@ Hashtbl.create 32
let some_task () =
(* RAII-ish, as above *)
let@ tbl = Lock.with_lock my_tbl in
Hashtbl.add tbl "cool" true
(* lock released here *)
We also have a similar wrapper called 'a Immlock.t, designed for immutable values
only. It’s a bit like a generalized 'a Atomic.t value.
The read path is a single atomic read, whereas the update path uses a
regular lock to serialize writers.
Writers don’t block readers, which will just read the current value.
Since our long lived values tend to be
immutable, a 'a Immlock.t can be used for intermediate computations, only
for its content to be returned as-is at the end.
(* immlock.ml*)
type 'a t = {
content: 'a Atomic.t; (** Quickly access immutable data *)
mutex: Mutex.t; (** only used for updates *)
}
let[@inline] get self = Atomic.get self.content
let update self f =
Mutex.protect self.mutex (fun a ->
let res = f (Atomic.get a) in
Atomic.set self.content res)
let update_map self f =
Mutex.protect self.mutex (fun a ->
let res, y = f (Atomic.get a) in
Atomic.set self.content res;
y)
Critical sections
Talking about locks, you know what’s bad? Holding a lock across an await.
Don’t do it. That’s it.
In general, critical sections
(the scope inside let@ foo = Lock.with_lock locked_foo in …)
must be as short and side-effect free as possible.
Thread-local storage
There still isn’t any official support for thread-local storage in OCaml despite various past attempts. I think it’s pretty unfortunate but meanwhile there’s a workaround implemented in a library. It has worked fine for us in various places in Moonpool, but it would be better to have official support in the long term.
Case study: Parse_import_graph
This might all be a bit abstract. We should look at an illustrative example
of what our use of Moonpool looks like in practice.
Imandrax has an in-file import syntax (instead of relying on a build system
like OCaml does. The syntax is, in the most basic case, [@@@import "foo/bar.iml"].
There are situations where we want to parse a file and transitively find all
its dependencies, each resolved into Abspath.t values (absolute, normalized file paths).
A slightly simplified version of the implementation
for that feature goes like this:
(** Imports for a given file *)
type per_file = {
imports: Import.t list; (** Resolved imports for this file *)
import_errors: (T_loc.t * Error.t) list; (** Import errors, with locations *)
}
[@@deriving show]
(** Result of analyzing the transitive import graph *)
type t = {
files: per_file Abspath.Map.t;
files_not_found: Str_set.t;
}
(** Internal state for the computation *)
type state = {
active: Switch.t;
runner: Moonpool.Runner.t;
not_found: Str_set.t Immlock.t;
files: per_file Abspath.Map.t Immlock.t;
files_seen: Abspath.Set.t Immlock.t;
}
(** Graph traversal *)
let rec analyze_file (self : state) (p : Abspath.t) : unit Moonpool.Fut.t =
(* closure to actually parse file at path [p], in a background task *)
let actually_run () : unit Moonpool.Fut.t =
let@ () = Moonpool.Fut.spawn ~on:self.executor in
let@ _trace_span =
Trace_async.with_span ~level:Info ~__FILE__ ~__LINE__
"parse-import.analyze-file"
~data:(fun () -> [ "path", `String (p :> string) ])
in
if Switch.is_off self.active then
Error.failf ~kind:Error_kind.interrupted "Interrupted.";
(* the actual parsing *)
let phrases, _, _ = Parsing.parse_file ~path:p () in
let imports, import_errors = Parsing.imports_of_phrases phrases in
(* save result *)
let per_file = { imports; import_errors } in
Immlock.update self.files (Abspath.Map.add p per_file);
(* analyze imports in sub-tasks, in parallel,
and wait for them to terminate *)
List.map
(fun (imp : Import.t) ->
analyze_file self (imp.import_abs_path :> Abspath.t))
imports
|> List.iter Moonpool.Fut.await
in
let already_processed =
(* atomically check if we're the first task to check this file,
and if so add it to the set of processed files *)
Immlock.update_map self.files_seen (fun s ->
Abspath.Set.add p s, Abspath.Set.mem p s)
in
if already_processed then
Moonpool.Fut.return () (* no-op *)
else
actually_run ()
let run ~active ~runner ~(file : Abspath.t) () : t Error.result =
(* catch errors, returns results *)
let@ () = Error.guards "parsing import graph" in
let@ _trace_span =
Trace.with_span ~__FILE__ ~__LINE__ "parse-import-graph.main"
in
let st : state = {
active;
runner;
not_found = Immlock.create Str_set.empty;
files = Immlock.create Abspath.Map.empty;
files_seen = Immlock.create Abspath.Set.empty;
} in
analyze_file st file |> Moonpool.Fut.await;
{
files_not_found = Immlock.get self.not_found;
files = Immlock.get self.files;
} in
As we can see, the graph traversal relies on Fut.spawn to explore
the dependencies of the current file in parallel, it has some shared
state that relies on Immlock.t (to make sure we don’t explore a
file more than once), there’s a layer of tracing
using ocaml-trace,
and a basic form of cancellation handling using a Switch.t.
This version doesn’t warn the user upon cyclic dependencies but we do check for that at typechecking.
What about async IOs?
I’ll keep this section relatively short. The gist is: we still currently use blocking IOs as our system is generally CPU-bound. For HTTP handlers, we spawn a thread (some HTTP endpoints use a websocket, potentially long lived, which would quickly starve a thread pool.) For local file IOs and the LSP, threads are more than enough.
Still, we are experimenting with
Moonpool_lwt
(announced here),
a Moonpool.Runner.t that runs on, and wraps, Lwt_main.run.
It is compatible with all the Moonpool concurrency primitives we
use (including await-ing futures that run on the various background thread pools),
but also await-ing any Lwt.t promise, such as IO primitives that are handled by
the Lwt event loop (backed by epoll on Linux.)
We could also use any Lwt-based library such as Dream, but still
write each HTTP handler in direct style.
We’re not using Eio mostly because it’s not (yet?) compatible with Moonpool, and is an opinionated large library in itself. Our initial needs were driven by parallelization, not something Eio was designed for.
Conclusion
That was quite a lot! It’s great to finally have multicore support in OCaml, but the ecosystem and best practices around it are still solidifying, and various people and groups are exploring alternative libraries and approaches. For us, Moonpool has been working fairly well.
-
The two main features for concurrency are algebraic effects, which enables libraries to implement an
awaitlike system; and the multicore GC which enables true shared-memory parallelism. We use both in Moonpool. ↩ -
for more information about imandrax, here is a 2020 talk about imandrax’s predecessor. Most of the logic/language features are similar, but the architecture and usage patterns have changed from single-threaded bytecode REPL, to LSP/HTTP API servers. ↩
-
This might change in favor of Eio at some point. ↩
-
name is still subject to change since Moonpool isn’t 1.0 yet. ↩
-
We do content-addressing on the main tasks (proof obligations, decompositions, etc) for storage and caching purposes, using Blake3. ↩